Binary Deobfuscation: Preface
Table of Contents
- A Short Introduction
- Some Ground-Rules
- The Roadmap
- A Conclusion, For Now
- Additional Reading
- References
A Short Introduction
Hello.
My name is Cal, and as you read initially, this is a place for me to organize my thoughts.
For a long time, I have been meaning to throw together some information regarding binary obfuscation. This post is going to be a preface to my journey exploring a variety of different protectors, the protections they provide (in terms of obfuscation), and how anybody with a little time and patience can overcome them.
It’s my sincere hope that, by the end of my writing, both you and I may walk away with something remarkable: not just the tooling to break modern, existing binary obfuscations, but a more fundamental understanding behind the ideas that create them. The ability to manipulate obfuscated binary objects in a way not bound by time, or a specific implementation; that is what I’m hoping to forge.

Some Ground-Rules
I’m not interested in using paid, existing tools. This is something I feel alienates at-least a portion of readers, and I’m against it. So kiss your pirated version of IDA goodbye, and strap in.
Also, the contents of this series will largely revolve around samples of x64 binaries built for Windows, but the tooling may not. In the spirit of being fair to readers, and advancing my own knowledge of Linux binaries, I’ll do my best to write some posts in that area as well; and mix the two when warranted.
The Roadmap
As an initial exercise, I’d like to explore Obfuscator-LLVM (OLLVM). This will allow us to build multiple, flexible examples of specific binary obfuscations, and understand what goes into both making and breaking them. This will also serve as a primer for LLVM’s intermediate representation (IR), and how we can leverage it to better understand our programs.
Once we have the groundwork for the rest of our research put in place, we will begin analyzing larger, more developed commercial protectors. Therein, I hope to put the techniques obscuring program function into context with the aforementioned OLLVM work.
Lastly, I hope to demonstrate the results of my research by using live, in-the-wild samples of binary obfuscation. This research would mean nothing to me, should it stay within the confines of meticulously arranged examples; and it certainly wouldn’t mean anything to you. Let’s just hope I find a way to evade lawsuits as we go.
Meet The Enemy
Speaking of lawsuits, below contains a list of software protectors that have caught my attention. As you may come to notice, there is quite a bit of overlap in terms of the protections they supply. This was intentional, as I hope to elaborate on certain obfuscation techniques in the context of multiple providers before focusing on one specifically.
Commercial Protectors
- Obfuscator-LLVM (OLLVM) (*) - https://github.com/obfuscator-llvm/obfuscator/wiki
- The Tigress C Diversifier/Obfuscator (*) - http://tigress.cs.arizona.edu/index.html
- ReWolf’s Virtualizer (*) - https://github.com/rwfpl/rewolf-x86-virtualizer
- ASProtect - http://www.aspack.com/asprotect64.html
- Obsidium - https://www.obsidium.de/show/details/en
- PELock - https://www.pelock.com/products/pelock
- Enigma Protector - https://enigmaprotector.com/
- CodeVirtualizer - https://www.oreans.com/codevirtualizer.php
- Themida - https://www.oreans.com/themida.php
- VMProtect - https://vmpsoft.com/
- GuardIT - https://www.arxan.com/application-protection/desktop-server
(*) Non-commercial applications
Now, this is a list of (primarily) commercial protectors. It goes without saying, but it’s important to note: there are other examples of obfuscation out in the world of binaries, some of which have never been processed by commercial protection apps. Don’t be mistaken: these examples are not out of the scope of our research by any means. Below I have listed some of such examples.
The Real Enemy
- ZeusVM - https://en.wikipedia.org/wiki/Zeus_(malware)
- FinSpy VM - https://en.wikipedia.org/wiki/FinFisher
- Nymaim - https://www.cyber.nj.gov/threat-profiles/trojan-variants/nymaim
- Smoke Loader - https://www.cyber.nj.gov/threat-profiles/trojan-variants/smoke-loader
- Swizzor - https://en.wikipedia.org/wiki/Swizzor
- APT10 ANEL - https://en.wikipedia.org/wiki/Red_Apollo
- xTunnel - https://en.wikipedia.org/wiki/Fancy_Bear
- Uroburos/Turla - https://en.wikipedia.org/wiki/Turla_(malware)
When people mention binary obfuscation, malware is a very easy conclusion to arrive at. There is another side to that coin, though, and our list wouldn’t be complete without it. Below are the examples of ‘legitimate’ obfuscation I’ve collected. These are companies looking to obscure the inner workings of their code for reasons that range from monetary incentive, to consumer protection (or so they say).
‘Legitimate’ Obfuscation
- Skype - https://www.skype.com/en/
- Spotify (See also Widevine) - https://www.spotify.com/us/
- Adobe Photoshop - https://www.adobe.com/products/photoshop.html
- BattlEye - https://www.battleye.com/
- EasyAntiCheat - https://www.easy.ac/en-us/
- Windows PatchGuard/Kernel Patch Protection - https://en.wikipedia.org/wiki/Kernel_Patch_Protection
Quick note: some of the above applications have been protected via entries in our commercial protectors list. In the event that the obfuscation implemented by these applications too closely resembles output from our commercial protectors, it will be stated, and subsequently omitted from future posts.
Techniques, Topics, and Prevalence
In this section, I am going to outline the obfuscation techniques used by the above applications, and arrange a table to represent the prevalence of said techniques.
Instruction Substitution
Also known as instruction mutation,
“… this obfuscation technique simply consists in replacing standard binary operators (like addition, subtraction or boolean operators) by functionally equivalent, but more complicated sequences of instructions” 1
While I believe OLLVM’s description of this technique gets the point across, I would like to generalize it a bit. However this technique is implemented, it carries the primary objective of changing the content of the code, while retaining the original semantics. This technique isn’t limited to numerical operations. As long as the result of the transformation is functionally equivalent to the original, the implementation is entirely up to the creator.
Let’s look at some examples of how this might work.
mov eax, 1337h
The above assembly snippet might be transformed into something like the following:
add eax, 266Ch
shr eax, 1h
inc eax
While the two snippets may look different, they are functionally equivalent. Below I have included the various phases of an example function as it transforms under OLLVM’s instruction substitution pass.



Control Flow Flattening
Also known as CFG flattening or CFF,
The purpose behind control flow flattening is “to completely flatten the control flow graph of a program” 2
The control flow graph here refers to the various graphs generated by analysis tools which show a programs layout in the form of basic blocks.
Further,
“In a control-flow graph each node in the graph represents a basic block, i.e. a straight-line piece of code without any jumps or jump targets; jump targets start a block, and jumps end a block. Directed edges are used to represent jumps in the control flow. There are, in most presentations, two specially designated blocks: the entry block, through which control enters into the flow graph, and the exit block, through which all control flow leaves.” 3



Indirect Branches
An indirect branch,
“… rather than specifying the address of the next instruction to execute, as in a direct branch, the argument specifies where the address is located” 4
An easy way to think of this is an instruction sequence like the following:
mov eax, function_address
...
jmp eax
Here is an example of an indirect branch, taken out of one of the above programs. This program is riddled with branches that look just like this; and at the time, IDA was not able to follow them.


Opaque Predicates
“an opaque predicate is a predicate—an expression that evaluates to either “true” or “false”—for which the outcome is known by the programmer … but which, for a variety of reasons, still needs to be evaluated at run time” 5
Opaque predicates are a particularly nasty form of control flow obfuscation. They come in all shapes and sizes, and determining the opaque-ness of a predicate can sometimes prove to be quite a challenge.
To expand on the above explanation, in the context of an obfuscated binary this “true” or “false” expression is evaluated in the form of a conditional branch. Below I have included a small example of an opaque predicate.
mov eax, 4h
...
cmp eax, 4h
je label_1
mov eax, 224h ; * this will never execute
jmp label_187 ; *
label_1:
mov eax, 22h
...
Now, as you may expect, this is not a realistic example of an in-the-wild opaque predicate. However, this example does illustrate the idea of using conditional branches to obfuscate the control flow of a program. And while this example is clearly quite simple, most implementations of the technique are not. For instance, the form of opaque predicate above is sometimes referred to as an invariant opaque predicate. 6 There are also contextual opaque predicates, whose value is not self-contained, but which relies on the value of an external variable (invariant). 6 Which isn’t to forget about dynamic opaque predicates, which are part of a grouping of predicates, arranged in such a way that all possible paths perform the same underlying functionality. 6 7 This is all just the tip of the iceberg.
Opaque predicates also routinely cause problems within analysis platforms when certain assumptions are made. For instance, IDA Pro is one example of a tool that expects nice, proper code. 8 Below I have included an example of what can happen when you violate the assumptions made during IDA’s binary analysis.




As you can see in the above demonstration, even simple attempts at disrupting analysis tools can greatly modify the output. Here, IDA made the assumption that the one dummy data byte in our opaque predicate was an opcode expansion prefix forcing the instruction to require at-least one more byte. This next byte, of course, chipped into the real instruction that would be executed.
If one wasn’t paying attention, you might miss that IDA signaled to this transformation in the instruction jz short near ptr loc_40100E+1 where the +1 at the end would tell an attentive reverse engineer that the initial branch skips one byte at it’s target location. Below, I have shown a very simple fix for this transformation.

Function Inlining
“In computing, inline expansion, or inlining, is a manual or compiler optimization that replaces a function call site with the body of the called function” 9
Function inlining is a well known compiler optimization technique. 10 It shouldn’t surprise you to learn, when used inappropriately, and interwoven with our other obfuscation techniques, inline expansion can become a rather effective means of obfuscation. Take the following example:
int bar (int val)
{
return val * 2;
}
int foo (int a, int b)
{
int c = bar(b);
return a + c;
}
In order to reduce overhead from that call, your compiler may perform inline expansion and allow the function bar to be inlined into foo, shown below:
int foo (int a, int b)
{
int c = b * 2;
return a + c;
}
Which could, of course, further reduce by removing the dependency on variable c, but you get the point.
Now, imagine instead of multiplying a number by two, the function bar was responsible for logging runtime information to a file. In this hypothetical logging function, suppose we also decide to implement some menial logic regarding the type of information we’re logging. If the function foo now were to call this logging function, even just a couple times, you can already begin to imagine how much our function would expand on the source level; not to mention the disassembly.
It’s ironic: the most effective means to simplifying function inlining is also used as an obfuscation technique.
Function Outlining
“Outline pieces of a function into their own functions” 11
Synonymous with function splitting, the definition (and further implementation) of function outlining is broad. Some protectors will simply divvy up a function’s basic blocks; which will then retain a direct one-to-one relationship within their parent function. Some other protectors create entirely new functions, utilized by multiple different callers. For instance, take the following diagram:
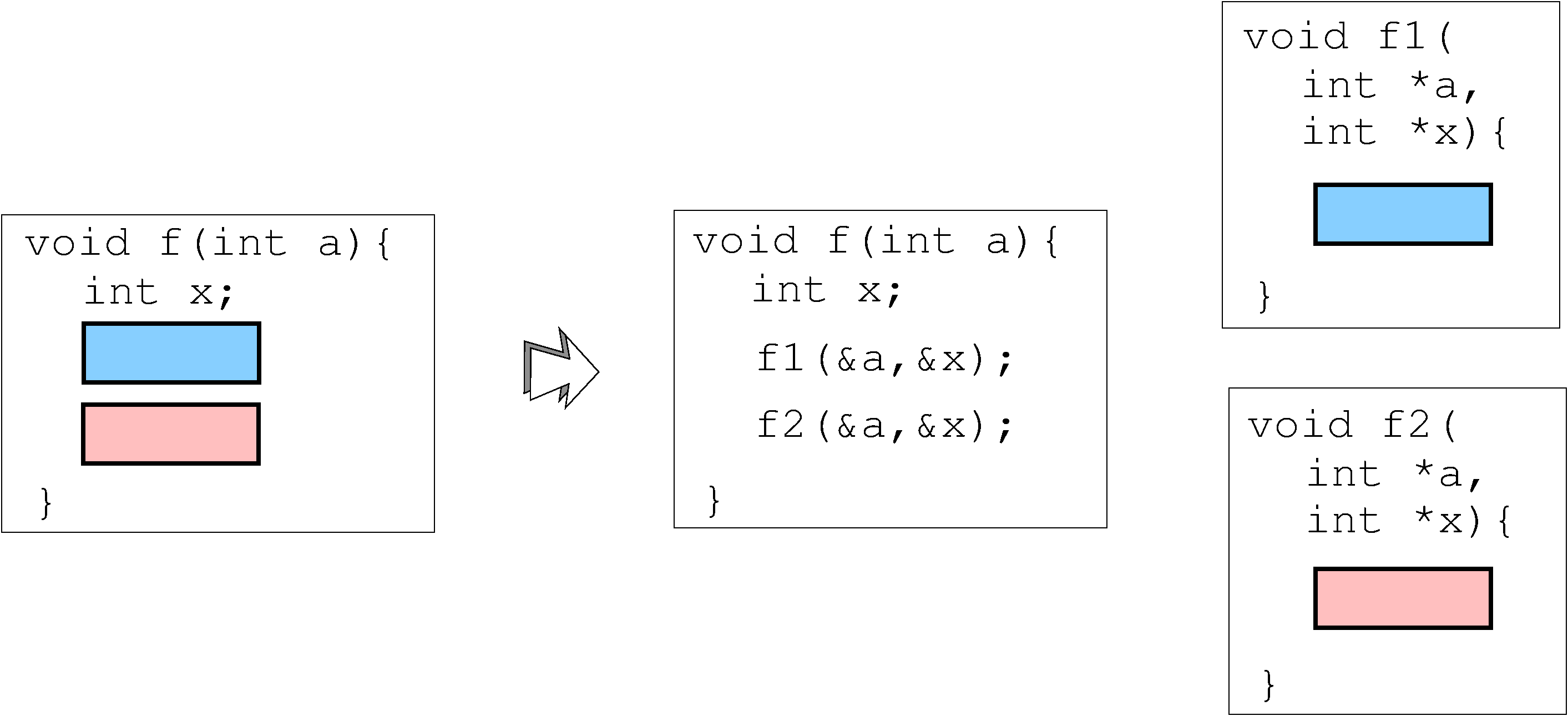
The above image is to imply that the new functions, f1 and f2, may contain code that isn’t present within the original function f (such as a prologue and epilogue). This transformation would then enable other functions, which may rely on the functionality of f1 or f2, to omit their own code and rely on an outlined function instead.
Later down the road, we will investigate how exactly this feature is implemented by Tigress. In the meantime, we can make an interesting comparison to OLLVM. Unlike Tigress’ implied function outlining implementation, OLLVM behaves in the exact opposite manner. OLLVM’s disassembly would retain a direct, one-to-one relationship with it’s parent, in the event of a splitting pass.
Dead Code
“…dead code is a section in the source code of a program which is executed but whose result is never used in any other computation” 12
Additionally, it may be important to note: the registers dead code uses throughout it’s life cycle are sometimes referred to as dead registers.!
Here, I have included a small assembly snippet which includes only functional code.
mov eax, 2h
add eax, 2h
cmp eax, 4h
...
Below, I have reworked our above example with a few instructions that correspond to our above definition of dead code. These instructions are marked with asterisks.
mov ebx, 24h ; *
mov eax, 2h
add ebx, 12h ; *
add eax, 2h
mov ecx, ebx ; *
inc ecx ; *
cmp eax, 4h
...
Since the dead code above occupies the registers ebx and ecx, these registers can now be considered dead. However, that isn’t to say these registers will always remain dead. The occupation of non-dead, living code, would indeed restore the status of ebx and ecx.
Junk Code
Also known as unreachable code,
“… is part of the source code of a program which can never be executed because there exists no control flow path to the code from the rest of the program” 13
One of the things the above snippet fails to recognize, is that in the event of an opaque predicate whose secondary condition never executes, there would exist a control flow path to it’s location. I have created an example of this below.
mov eax, 4h
...
cmp eax, 4h
je label_1 ; (A)
mov ecx, 1h ; * this will never execute
sub ebx, ecx ; *
push ebx ; *
call function_224 ; *
label_1: ; (B)
...
The instructions nested between the conditional jump (A) and our first label (B) are junk code; they’ll never execute. However, this doesn’t stop a control flow path from existing to their location.
Constant Folding
In order to understand the idea of constant unfolding (seen below), you must first understand the idea of constant folding.
“Constant folding is the process of recognizing and evaluating constant expressions at compile time rather than computing them at runtime.” 14
Suppose we started with a piece of code like the following:
int x = 220;
int y = (x / 2) + 1;
Constant folding, in this case, is just the reduction of the expression pointed to by our variable y at compile time:
int x = 220;
int y = 111;
As stated above, constant folding is a form of optimization performed by compilers. Directly, this is not a technique that commonly corresponds to code obfuscation!; but given the context, constant folding could very much be used as a means to obscure code function; as is the case with many compiler optimizations.
Constant Unfolding
While both constant folding and constant unfolding can be used as an obfuscation technique, constant unfolding is more commonly seen.!
Given the example of constant folding above, I have constructed a more intricate example of constant unfolding below. Something to keep in mind: although constant folding and unfolding seem easy to deal with, don’t let this fool you. Remember, the strength usually lies in the implementation.
int x = 220;
int y = (((x - 0xAA) | 0x58) ^ (((((x / 4) * 0x138759) >> 0x10) & 0x11) + 0x6)) + 0x3;

So, for a minute now, imagine the above arithmetic is done in assembly, amid other operations, across a flattened function, all while being executed through a custom virtual machine.
Oh, right…
Virtualization
“In computing, a virtual machine (VM) is an emulation of a computer system” 15
That’s It.
The virtual machines used in code obfuscation aren’t like VMware or VirtualBox. They don’t make use of technologies like AMD-V or Intel VT-x (thankfully). Instead, the virtual machines found within obfuscated binaries are simply interpreters.!
The original, non-virtualized code of the underlying binary has been transformed into a custom bytecode. This custom bytecode is fed to an interpreter, whose job it is to mimic the actions of said underlying binary.

Above, I have included a screenshot from the commercial protector, CodeVirtualizer. As you can see, the simplistic code on the left is transformed into an entirely different instruction set on the right.
I understand the above explanation is lacking. The problem with going into detail on this obfuscation technique now is the potential for variability in it’s implementation. So, let’s put a pin in it. I will go into considerably more detail on this technique in the posts to come.
Self Modification
“In computer science, self-modifying code is code that alters its own instructions while it is executing …” 16
There isn’t any more I’d like to say about this technique now. Like the above, the implementation defines the strength of the obfuscation.
This is a technique I am excited to explore, though, as it will involve us creating some examples to work off of.
Jitting
Lastly, I want to briefly discuss the concept of jitting.
“In computing, just-in-time (JIT) compilation (also dynamic translation or run-time compilations) is a way of executing computer code that involves compilation during execution of a program – at run time – rather than prior to execution.” 17
There is a lot to be said about the potential for this technique. It’s one that I believe is only used in the Tigress C Diversifier. This is also a technique we will be expanding on within examples that we create.
Interestingly, Tigress also includes the ability to implement a transformation called JitDynamic, which “… is similar to the Jit transformation, except the jitted code is continuously modified and updated at runtime” 18. This technique would then be better classified as self modifying code.
Now is a good time to state, I have not yet reversed all of the above applications. The table below is based largely on information I have read from others; and cited accordingly. Data lacking of citations is largely speculative, or backed by research I have conducted that will not be made public. The applications, the techniques, and their ordering are all subject to change. In time, this snippet will be replaced, and citations to my own research will be used in place of the existing ones below. For now, take everything in the table below with a grain of salt, and read up on those citations (if there are any).
Commercial Obfuscations
| Application | Instruction Substitution | Control Flow Modification | Indirect Branches | Opaque Predicates | Function Inlining | Function Outlining | Dead Code | Junk Code | Constant Unfolding | Virtualization | Self Modification | Jitting |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tigress | ✅19 | ✅19 | ✅19 | ✅19 | ✅19 | ✅19 | ✅19 | ✅19 | ✅19 | ✅19 | ✅19 | ✅19 |
| Themida | ✅20 | ✅! | ✅! | ✅! | ❌! | ✅! | ✅! | ✅! | ✅! | ✅20 | ❌! | ❌! |
| VMProtect | ✅21 | ✅! | ✅! | ✅21 | ❔ | ✅21 | ✅21 | ✅21 | ✅! | ✅21 | ❌! | ❌! |
| GuardIT | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ |
| PELock | ✅22 | ✅22 | ✅22 | ✅22 | ❌! | ✅22 | ✅22 | ✅22 | ❌! | ❌! | ❌! | ❌! |
| OLLVM | ✅23 | ✅24 | ❌! | ✅25 | ❌! | ✅24 | ❌! | ✅25 | ✅23 | ❌! | ❌! | ❌! |
| CodeVirtualizer | ✅26 | ❌! | ❌! | ❌! | ❌! | ❌! | ❌! | ❌! | ❌! | ✅26 | ❌! | ❌! |
| ReWolf’s Virtualizer | ❌! | ❌! | ❌! | ❌! | ❌! | ❌! | ❌! | ❌! | ❌! | ✅27 | ❌! | ❌! |
| Enigma Protector | ✅28 | ❔ | ❔ | ❔ | ❌! | ❔ | ❔ | ❔ | ❔ | ✅28 | ❌! | ❌! |
| Obsidium | ❌! | ❔ | ❔ | ❔ | ❌! | ❔ | ❔ | ❔ | ❔ | ✅29 | ❌! | ❌! |
| ASProtect | ❌! | ❔ | ❔ | ✅30 | ❌! | ❔ | ❌! | ✅30 | ❔ | ❌! | ❌! | ❌! |
Malware Obfuscations
| Application | Instruction Substitution | Control Flow Modification | Indirect Branches | Opaque Predicates | Function Inlining | Function Outlining | Dead Code | Junk Code | Constant Unfolding | Virtualization | Self Modification | Jitting |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ANEL | ❌! | ✅31 | ✅31 | ✅31 | ❌! | ❌! | ✅31 | ✅31 | ✅31 | ❌! | ❌! | ❌! |
| Smoke Loader | ❌! | ✅32 | ❔ | ✅32 | ❌! | ✅32 | ❌! | ❔ | ❔ | ❌! | ✅32 | ❌! |
| Nymaim | ❌! | ✅33 | ✅33 | ✅34 | ❌! | ❌! | ❔ | ❔ | ✅34 | ❌! | ❌! | ❌! |
| xTunnel | ❌! | ❔ | ❔ | ✅35 36 | ❌! | ❌! | ✅37 | ✅35 | ❔ | ❌! | ❌! | ❌! |
| Uroburos/Turla | ❌! | ❔ | ❔ | ✅38 | ❌! | ❌! | ❔ | ✅38 | ❔ | ❌! | ❌! | ❌! |
| FinSpy VM | ❌! | ❔ | ❌! | ✅39 | ❌! | ❌! | ✅39 | ✅! | ✅39 | ✅40 39 | ❌! | ❌! |
| ZeusVM | ❌! | ❔ | ❔ | ❔ | ❌! | ❌! | ❔ | ❔ | ❔ | ✅41 | ❌! | ❌! |
| Swizzor | ❌! | ❔ | ❔ | ❔ | ❌! | ❌! | ✅42 | ❔ | ❔ | ❌! | ❌! | ❌! |
‘Legitimate’ Obfuscations
| Application | Instruction Substitution | Control Flow Modification | Indirect Branches | Opaque Predicates | Function Inlining | Function Outlining | Dead Code | Junk Code | Constant Unfolding | Virtualization | Self Modification | Jitting |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BattlEye | ✅! | ✅! | ✅! | ✅! | ❌! | ✅! | ✅! | ✅! | ✅! | ✅! | ❌! | ❌! |
| EasyAntiCheat | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ |
| Photoshop | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ |
| Spotify | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ | ❔ |
| PatchGuard | ❌! | ✅43 44 | ✅45 | ❔ | ❌! | ❌! | ❔ | ❔ | ❔ | ❌! | ✅46 | ❌! |
| Skype | ❌! | ✅47 | ✅47 | ✅47 | ❌! | ❌! | ❌! | ❔ | ❔ | ❌! | ❌! | ❌! |
Note: A lot of the above applications utilize various forms of control flow modifications that are not control flow flattening. As such, I have generalized that category in the table above.
A Conclusion, For Now
I have made some bold and ambitious statements in this post. Systems like PatchGuard are completely unknown to me. Malware like Turla and Sednit are state-sponsored threats with high-priority targets. Not to mention, the obfuscation employed by all of above is said to be challenging——very difficult to work through. There is a lack of easy, straightforward solutions; and the research to engineer such tooling is generally contained within academic circles.
There’s no doubt the road ahead is a long and challenging one. It will require me to learn a great deal about how these techniques are implemented, and how we can better go about circumventing them. Additionally, I am learning quickly that there are a myriad of legal obstacles in the way of my research. I want to make it clear: I don’t wish to be implicated in any legal manner for the sharing of this information, nor would I like to aid in the breaking of DRM schemes, or development of malware-focussed binary protection systems. So in the future, expect the methods I’ll use to share information with you to fall firmly within the bounds of what is fair, legal, and educational.
That being said, I make this promise to you now: my research will apply to modern binary obfuscation. I will not diverge from the goals I stated initially.
Additional Reading
Above I mentioned that the most notable research into binary deobfuscation is largely contained within academic circles. Usually these resources are dry, and difficult to read through. So, in the spirit of not bogging you down with boring and speculative research, below I have done my best to list resources that I found to be both practical and engaging.
- Diablo - Deobfuscation: By Hand (https://diablo.elis.ugent.be/node/54)
- The Tigress C Diversifier/Obfuscator: Transformations (http://tigress.cs.arizona.edu/transformPage/index.html)
- Intermediate Representation - Wikipedia (https://en.wikipedia.org/wiki/Intermediate_representation)
- Usenix - Disassembling Obfuscated Binaries (https://www.usenix.org/legacy/publications/library/proceedings/sec04/tech/full_papers/kruegel/kruegel_html/node3.html)
- Optimizing Compiler (Specific Techniques) - Wikipedia (https://en.wikipedia.org/wiki/Optimizing_compiler#Specific_techniques)
- Compiler Optimizations for Reverse Engineers - Rolf Rolles, Mobius Strip Reverse Engineering (https://www.msreverseengineering.com/blog/2014/6/23/compiler-optimizations-for-reverse-engineers)
- Udupa, Sharath K., Saumya K. Debray, and Matias Madou. “Deobfuscation: Reverse engineering obfuscated code.” 12th Working Conference on Reverse Engineering (WCRE’05). IEEE, 2005. (https://ieeexplore.ieee.org/abstract/document/1566145)
- Deobfuscation: recovering an OLLVM-protected program (https://blog.quarkslab.com/deobfuscation-recovering-an-ollvm-protected-program.html)
- Aspire - Publications (https://aspire-fp7.eu/papers)
- Creating Code Obfuscation Virtual Machines - RECon 2008 (https://www.youtube.com/watch?v=d_OFrP-m2xU)
References
-
Obfuscator-LLVM: Instruction Substitution - https://github.com/obfuscator-llvm/obfuscator/wiki/Instructions-Substitution ↩
-
Control Flow Flattening (Wikipedia) - https://github.com/obfuscator-llvm/obfuscator/wiki/Control-Flow-Flattening ↩
-
[PDF] Masking wrong-successor Control Flow Errors employing data redundancy - https://ieeexplore.ieee.org/abstract/document/7365827 ↩
-
Indirect Branch (Wikipedia) - https://en.wikipedia.org/wiki/Indirect_branch ↩
-
Opaque Predicate (Wikipedia) - https://en.wikipedia.org/wiki/Opaque_predicate ↩
-
Thomas Ridma. “Seeing through obfuscation: interactive detection and removal of opaque predicates.” In the Digital Security Group, Institute for Computing and Information Sciences. 2017. - https://th0mas.nl/downloads/thesis/thesis.pdf ↩ ↩2 ↩3
-
Palsberg, Jens, et al. “Experience with software watermarking.” Proceedings 16th Annual Computer Security Applications Conference (ACSAC’00). IEEE, 2000. - https://ieeexplore.ieee.org/document/898885 ↩
-
Hex-Rays: IDA and obfuscated code - https://www.hex-rays.com/products/ida/support/ppt/caro_obfuscation.ppt ↩
-
Inline Expansion (Wikipedia) - https://en.wikipedia.org/wiki/Inline_expansion ↩
-
Eilam, Eldad. *Reversing: Secrets of Reverse Engineering*. Wiley, 2005. Print. - https://www.wiley.com/en-us/Reversing%3A+Secrets+of+Reverse+Engineering+-p-9780764574818 ↩
-
The Tigress C Diversifier/Obfuscator: Function Splitting - http://tigress.cs.arizona.edu/transformPage/docs/split/index.html ↩
-
Dead Code (Wikipedia) - https://en.wikipedia.org/wiki/Dead_code ↩
-
Unreachable Code (Wikipedia) - https://en.wikipedia.org/wiki/Unreachable_code ↩
-
Constant Folding (Wikipedia) - https://en.wikipedia.org/wiki/Constant_folding ↩
-
Virtual Machine (Wikipedia) - https://en.wikipedia.org/wiki/Virtual_machine ↩
-
Self-Modifying Code (Wikipedia) - https://en.wikipedia.org/wiki/Self-modifying_code ↩
-
Just-in-time Compilation (Wikipedia) - https://en.wikipedia.org/wiki/Just-in-time_compilation ↩
-
The Tigress C Diversifier/Obfuscator: Dynamic Obfuscation - http://tigress.cs.arizona.edu/transformPage/docs/jitDynamic/index.html ↩
-
The Tigress C Diversifier/Obfuscator: Transformations - http://tigress.cs.arizona.edu/transformPage/index.html ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10 ↩11 ↩12
-
Oreans: Themida Overview - https://www.oreans.com/Themida.php ↩ ↩2
-
VMProtect Software Protection: What is VMProtect? - http://vmpsoft.com/support/user-manual/introduction/what-is-vmprotect/ ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
PELock: Software protection system - https://www.pelock.com/products/pelock ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
Obfuscator-LLVM: Instruction Substitution - https://github.com/obfuscator-llvm/obfuscator/wiki/Instructions-Substitution ↩ ↩2
-
Obfuscator-LLVM: Control Flow Flattening - https://github.com/obfuscator-llvm/obfuscator/wiki/Control-Flow-Flattening ↩ ↩2
-
Obfuscator-LLVM: Bogus Control Flow - https://github.com/obfuscator-llvm/obfuscator/wiki/Bogus-Control-Flow ↩ ↩2
-
Oreans: CodeVirtualizer Overview - https://oreans.com/CodeVirtualizer.php ↩ ↩2
-
[PDF] ReWolf’s x86 Virtualizer: Documentation - http://rewolf.pl/stuff/x86.virt.pdf ↩
-
The Enigma Protector: About - https://enigmaprotector.com/en/about.html ↩ ↩2
-
Obsidium: Product Information - https://www.obsidium.de/show/details/en ↩
-
David, Robin, Sébastien Bardin, and Jean-Yves Marion. “Targeting Infeasibility Questions on Obfuscated Codes.” arXiv preprint arXiv:1612.05675 (2016). - https://arxiv.org/pdf/1612.05675 ↩ ↩2
-
Carbon Black: Defeating Compiler-Level Obfuscations Used in APT10 Malware - https://www.carbonblack.com/2019/02/25/defeating-compiler-level-obfuscations-used-in-apt10-malware/ ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
CERT.PL: Dissecting Smoke Loader - https://www.cert.pl/en/news/single/dissecting-smoke-loader/ ↩ ↩2 ↩3 ↩4
-
ESET: Dymaim Obfuscation Chronicles - https://www.welivesecurity.com/2013/08/26/nymaim-obfuscation-chronicles/ ↩ ↩2
-
CERT.PL: Nymaim Revisited - https://www.cert.pl/en/news/single/nymaim-revisited/ ↩ ↩2
-
[PDF] ESET: En Route with Sednit (Part 2) - https://www.welivesecurity.com/wp-content/uploads/2016/10/eset-sednit-part-2.pdf ↩ ↩2
-
[PDF] Sebastien Bardin, Robin David, Jean-Yves Marion. “Deobfuscation: Semantic Analysis to the Rescue”. Presentation at Virus Bulletin (2017). - https://www.virusbulletin.com/uploads/pdf/conference_slides/2017/Bardin-VB2017-Deobfuscation.pdf ↩
-
[PDF] Robin David, Sebastien Bardin. “Code Deobfuscation: Intertwining Dynamic, Static and Symbolic Approaches”. Presentation at BlackHat Europe (2016). - https://www.robindavid.fr/publications/BHEU16_Robin_David.pdf ↩
-
[PDF] ESET: Diplomats in Easter Europe Bitten by a Turla Mosquito - https://www.eset.com/me/whitepapers/eset-turla-mosquito/ ↩ ↩2
-
Mobius Strip Reverse Engineering: A Walk-Through Tutorial, with Code, on Statically Unpacking the FinSpy VM (Part One, x86 Deobfuscation) - https://www.msreverseengineering.com/blog/2018/1/23/a-walk-through-tutorial-with-code-on-statically-unpacking-the-finspy-vm-part-one-x86-deobfuscation ↩ ↩2 ↩3 ↩4
-
Github: Rofl Rolles’ Static Unpacker for FinSpy VM - https://github.com/RolfRolles/FinSpyVM ↩
-
Miasm’s Blog: ZeusVM Analysis - https://miasm.re/blog/2016/09/03/zeusvm_analysis.html ↩
-
Pierre-Marc Bureau, Joan Calvet. “Understanding Swizzor’s Obfuscation Scheme”. Presentation at RECon (2010). - https://archive.org/details/UnderstandingSwizzorsObfuscationScheme-Pierre-marcBureauAndJoanCalvet ↩
-
CSDN iiprogram’s Blog: Pathguard Reloaded, A Brief Analysis of PatchGuard Version 3 - https://blog.csdn.net/iiprogram/article/details/2456658 ↩
-
Uninformed: Subverting Patchguard Version 2; Obfuscation of System Integrity Check Calls via Structured Exception Handling - http://uninformed.org/index.cgi?v=6&a=1&p=8 ↩
-
Uninformed: Subverting Patchguard Version 2; Anti-Debug Code During Initialization - http://uninformed.org/index.cgi?v=6&a=1&p=5 ↩
-
Uninformed: Subverting Patchguard Version 2; Overwriting PatchGuard Initialization Code Post Boot - http://uninformed.org/index.cgi?v=6&a=1&p=12 ↩
-
[PDF] Philippe Biondi, Fabrice Desclaux. “Silver Needle in the Skype”. Presentation at BlackHat Europe (2006). - https://www.blackhat.com/presentations/bh-europe-06/bh-eu-06-biondi/bh-eu-06-biondi-up.pdf ↩ ↩2 ↩3